Lately, some people said that SQL has nothing common with the analysis. Are they right? Nope.
Analysts – bravest guys, who look at the numbers and doing good for everyone. And these numbers must make sense.
We are keeping them in the databases: sometimes relational, sometimes not. If the database is relational we can aggregate data with the help of SQL, which is always in touch.
Why we need to aggregate data? Because raw data is detrimental to health. Most of the time relational database is normalized. This means that for every entity (client, order, product, country, etc.) we have a different table. And we specify relations between tables. The idea of normalization is to decrease the size of the data. In addition, we will not be afraid of data desynchronization: when it comes to changing the product title (because of an error or change in business logic), which we keep in the different tables we will need to parse all these tables and change the title in every row. This will increase the probability of error and make our work unnecessary harder.
On the other side, the disadvantage of normalization is strong dispersion of the data. Thus, we are loosing the opportunity of simple 'select * from table' query. And we are forced to learn SQL-kung fu.
So, do we need SQL? Hell, yeah! Also, Excel can't work with more than 1kk rows. LibreOffice and other spreadsheet editors have even more ridiculous limits: 65k rows. Not much for serious data analysis.
Today we will imagine ourselves in the role of the e-commerce analyst. We need to make a small annual report.
Things we need in the report: order number, costs by an order, prices in order, margin, number of positions, payment type, order date, information about deliveries: address, price, company.
Some of these data connect directly with orders: order number, payment type and delivery information. Some with order positions: prices, costs, margin. So, first of all we should split the task:
1) get all information connected with the order;
2) get all information connected with order positions.
Then we will join results.
We need next tables: orders, positions, delivery.
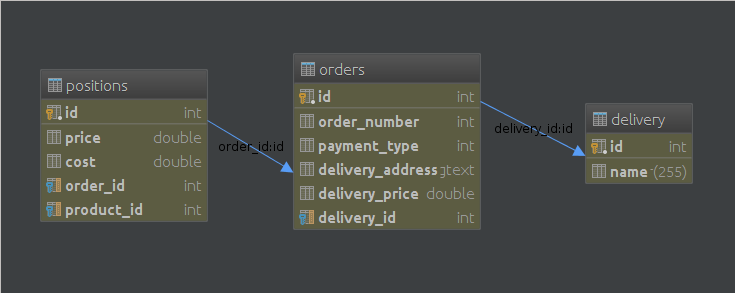
Let's make some queries :)
SELECT
o.order_number,
o.payment_type,
o.delivery_address,
o.delivery_price,
o.order_date,
d.name
FROM orders o
JOIN delivery d
ON o.delivery_id = d.id
Almost every field is stored in the orders table. If there wasn't JOIN then whole query would be similar to 'select * from orders'.
Moving to the next part, we will use something that I like: GROUP BY clause. Also, aggregate functions and some math expressions.
SELECT
p.order_id,
SUM(p.price),
SUM(p.cost),
1 - (SUM(p.cost)/SUM(p.price)) as margin,
COUNT(p.id)
FROM positions p
GROUP BY p.order_id
Now we're keeping 2 parts of our task in the hands. The last step to money and glory is their connection. Easy to guess that we are going to use JOIN based on order id.
SELECT
o.order_number,
o.payment_type,
o.delivery_address,
o.delivery_price,
o.order_date,
d.name,
p_info.price,
p_info.cost,
p_info.margin,
p_info.p_number
FROM orders o
JOIN delivery d
ON o.delivery_id = d.id
JOIN (
SELECT
p.order_id order_id, SUM(p.price) price,
SUM(p.cost) cost,
1 - (SUM(p.cost)/SUM(p.price)) margin,
COUNT(p.id) p_number
FROM positions p
GROUP BY p.order_id
) as p_info
ON p_info.order_id = o.id
Finally, our task is solved. Don't forget about aliases for fields in subquery. It simplifies their calling from outer select clause. We also could add extra conditions to the query: dates, transportation types, payment types and etc.
The basic mistake one can make here is to use 'WHERE p.order_id = o.id' in subquery instead of GROUP BY. It's much slower. Also query lost its flexibility. Splitting tasks into the parts always a good way to solve the problem.
So, why we doing all this work? Of course for Bentley with driver and personal island. After getting the result we can export it to the Excel or other spreadsheet editor and make our summary analysis.